Workflow and Data Preparation
Conventional algorithms are designed to answer exactly one question. In contrast, machine learning algorithms, particularly deep learning models based on convolutional neural networks (CNNs), can be taught to "learn" patterns and be adapted to a wide variety of problems and tasks, such as denoising, super-resolution, and segmentation. However, whether deep or not, model training relies heavily on data. Without data, it is impossible for any machine learning algorithm to learn.
As shown in the following flowchart, three different data sets — the training set, the validation set, and the testing set — are used for training, fine-tuning a model, and testing.
Deep Learning workflow
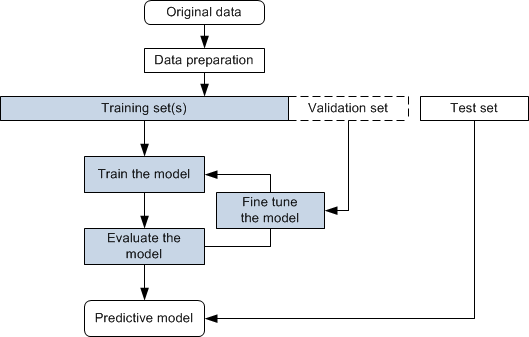
Data preparation is the process of selecting the right data to build a training set from your original data and making your data suitable for machine learning. Your original data may require a number of pre-processing steps to transform the raw data before training and validation sets can be extracted. Pre-processing steps can include cropping to isolate features of interest (see Cropping Datasets), extracting limited sized datasets from marked slices (see Extracting New Images from Marked Slices), and filtering to enhance images (see Image Filtering).
Note The quality of the training set will determine the performance of the predictive model.
Training sets, which are used to train a deep model to understand how to learn and apply concepts such denoising, super-resolution, and segmentation and to produce results, are the most crucial aspect that makes training possible. Training sets include the training input(s) and output(s), as well as an optional mask(s) and validation set. You should note that training sets typically make-up the majority of the total data, usually about 60 to 80%, and that for many projects, classifying and labeling data often takes the most time. During training, models are fit to parameters in a process that is known as adjusting weights.
A well-known issue for data scientists, overfitting is a modeling error which occurs when a function is too closely fit to a limited set of data points.
All projects are unique and this requirement needs to be evaluated based on the model being built. As a general rule, the more complicated the task, the more data that is needed.
It can happen that you lack the data required to integrate a deep learning solution. In this case, the Deep Learning Tool provides the option to artificially augment the available data when you set the model training parameters (see Data Augmentation Settings).
The test data set is used to evaluate how well the predictive model was trained with the training set. In deep learning projects, the training set cannot be used in the testing stage because the algorithm will already know in advance the expected output.
Information about training deep models for tasks such as segmentation, denoising, and super-resolution is available in the following topics:
- Training Deep Models for Denoising.
- Training Deep Models for Semantic Segmentation.
- Training Deep Models for Super Resolution.